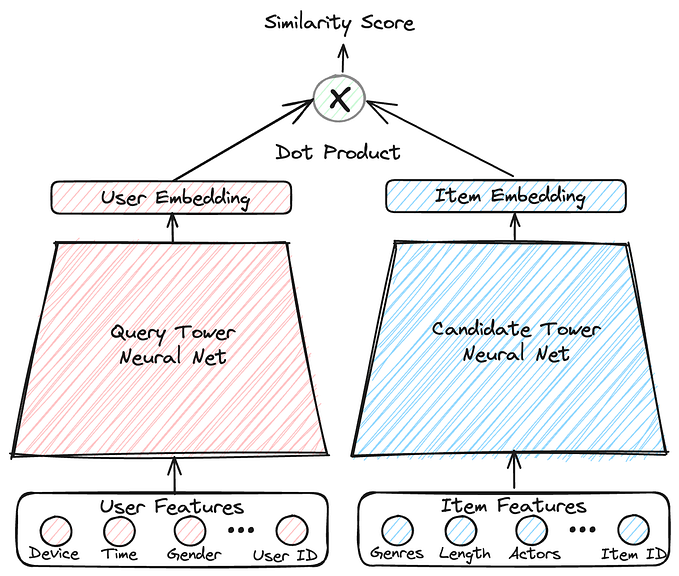
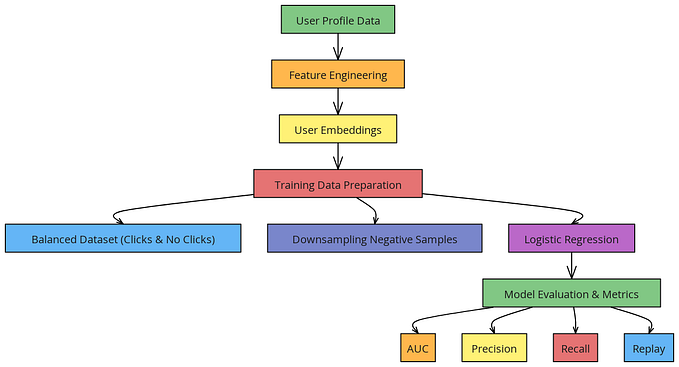
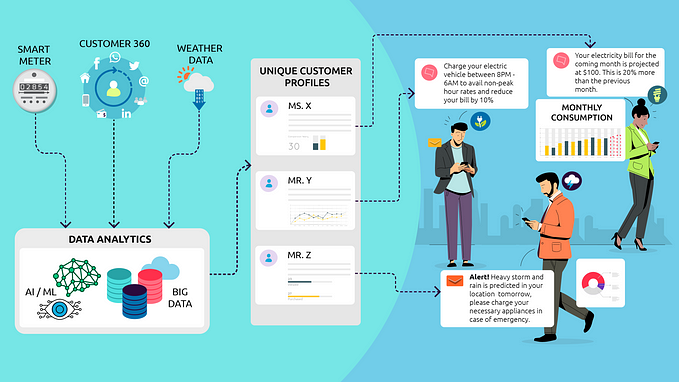
Deep Dive Into Machine learning : Recommender System
Note: While learning the topic, I prepared the note for my easy reference by referring various sources. Hopefully, this will be helpful to others too to understand the algorithm in the simple manner.

What is Recommender System:
A recommender system is a machine learning algorithm that uses data to suggest products or services to users. They are a popular data science application that many major tech companies use.
What are the types of Recommender System:
- Simple recommenders: Based on a product’s popularity or rating score
- Content-based recommenders: Suggest similar items based on metadata like a movie’s genre, director, or actors
- Collaborative filtering engines: Predict a user’s preferences based on other users’ past ratings and preferences
When to use Recommender System:
Recommender system is used in various scenarios.
- Improve user experience:
By providing personalized recommendations, you can help users discover relevant items they might not have found on their own, leading to increased engagement and satisfaction.
- Increase sales and revenue:
Recommender systems can drive sales by suggesting products that users are likely to purchase.
- Boost user engagement:
Recommender systems can keep users engaged by providing them with new and interesting content.
- Improve customer retention:
By providing relevant recommendations, you can make users feel more valued and encourage them to stay on your platform.
- Enhance decision-making:
Recommender systems can help users make informed decisions by providing them with relevant options.
What are the common use cases:
- E-commerce:
Recommending products to customers based on their browsing history, purchase history, or similar users’ behavior.
- Streaming services:
Suggesting movies, TV shows, or music based on user preferences and viewing/listening history.
- Social media:
Recommending friends, groups, or content based on user interests and interactions.
- News and content platforms:
Recommending articles, videos, or other content based on user reading history and interests.
- Job boards:
Recommending jobs to candidates based on their skills, experience, and interests.
When not to use Recommender System:
There are certain scenarios where they might not be the best fit.
1. Cold Start Problem:
- New Users:
When a new user joins the platform, there’s limited data about their preferences, making it challenging to provide accurate recommendations.
- New Items:
Similarly, when a new item is added, it lacks historical interaction data, hindering its visibility in recommendations.
2. Lack of Sufficient Data:
- If your dataset is too small or sparse, the recommender system might not be able to generate reliable recommendations.
- In such cases, simpler approaches like popularity-based recommendations might be more suitable.
3. Sensitive or Highly Personal Domains:
- In domains where privacy is a major concern (e.g., healthcare, finance), using a recommender system might raise ethical or legal issues.
- If the recommendations could have significant consequences for the user, you might want to consider alternative approaches that involve explicit user input or expert guidance.
4. High Cost of Implementation and Maintenance:
- Building and maintaining a recommender system can be complex and resource-intensive, especially for large datasets or sophisticated algorithms.
- If the potential benefits don’t outweigh the costs, it might be more practical to use simpler methods.
5. User Control and Transparency:
- Some users might prefer to have more control over their recommendations or understand the reasons behind them.
- Recommender systems that lack transparency or user control can be frustrating and lead to distrust.
6. Niche or Unique Items:
- If your items are highly unique or niche, it might be challenging for the recommender system to find relevant recommendations.
- In such cases, relying on expert curation or community-driven recommendations might be more effective.
7. Potential for Bias and Filter Bubbles:
- Recommender systems can inadvertently reinforce existing biases or create filter bubbles, limiting users’ exposure to diverse perspectives.
- If diversity and serendipity are important considerations, you might need to implement measures to mitigate these issues.
Steps to implement Recommender System:
import libraries:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
Read the dataframes
Read user dataframe
columns_names = [‘user_id’,’item_id’,’rating’,’timestamp’]
df = pd.read_csv(‘u.data’,sep=’\t’,names=columns_names)
Read movie dataframe
movie_titles = pd.read_csv(‘Movie_Id_Titles’)
Analyze the data frame
df.head()
df.columns
df.describe()
movie_titles.head()
movie_titles.columns
movie_titles.describe()
Merge
df = pd.merge(df,movie_titles,on=’item_id’)
Group by movie title
df.groupby(‘title’)[‘rating’].mean().sort_values(ascending=False).head()
df.groupby(‘title’)[‘rating’].count().sort_values(ascending=False).head()
Create ratings data frame
ratings = pd.DataFrame(df.groupby(‘title’)[‘rating’].mean())
ratings[‘num of ratings’] = pd.DataFrame(df.groupby(‘title’)[‘rating’].count())
plot histograms
ratings[‘num of ratings’].hist(bins=70)
ratings[‘rating’].hist(bins=70)
Joint plot
sns.jointplot(x=’rating’,y=’num of ratings’,data=ratings,alpha=0.5)
Create movie matrix
moviemat = df.pivot_table(index=’user_id’,columns=’title’,values=’rating’)
ratings.sort_values(‘num of ratings’,ascending=False).head(10)
starwar_user_ratings = moviemat[‘Star Wars (1977)’]
liarliar_user_ratings = moviemat[‘Liar Liar (1997)’]
similar_to_liarliar = moviemat.corrwith(liarliar_user_ratings)
corr_starwars = pd.DataFrame(similar_to_starwars,columns=[‘Correlation’])
corr_starwars.dropna(inplace=True)
corr_starwars.sort_values(‘Correlation’,ascending=False).head(10)
corr_starwars = corr_starwars.join(ratings[‘num of ratings’])
corr_starwars[corr_starwars[‘num of ratings’]>100].sort_values(‘Correlation’,ascending=False).head()
corr_liarliar = pd.DataFrame(similar_to_liarliar,columns=[‘Correlation’])
corr_liarliar.dropna(inplace=True)
corr_liarliar = corr_liarliar.join(ratings[‘num of ratings’])
corr_liarliar[corr_liarliar[‘num of ratings’]>100].sort_values(‘Correlation’,ascending=False).head()
Working Jupyter Notebook:
https://github.com/SwarnaPatel/Python_MachineLearning_RecommenderSystem